Understanding Consistent Hashing in Go: Implementation and Concepts
Learn how consistent hashing achieves uniform data distribution across dynamic server pools while minimizing data movement during scaling operations.
Have you ever wondered how distributed systems like Cassandra or Redis efficiently handle data distribution across thousands of servers?
I recently faced this challenge while building a distributed object storage system, and the solution led me down the path of consistent hashing.
My goal was to create a gateway that could consistently and statelessly distribute data across multiple servers.
This blog post will delve into the topic of consistent hashing, and how it helped me to solve the challenge at hand.
Understanding the Challenge
Before diving into consistent hashing, let's understand why traditional approaches fall short.
Imagine you're building a distributed cache or storage system that needs to:
- Distribute data uniformly across servers
- Minimize data redistribution when servers are added or removed
- Make routing decisions without maintaining state
- Handle server failures gracefully
At first, I looked into simple modulo hashing. It was OK for a use-case where the number of servers remains static, but that's rarely the case, is it? Let's see why.
1. Traditional Hash Distribution
A hash map, at its core, is a mathematical formula that will always give you the same output, for the same input, regardless of what happened before, or comes after.
In the context of a distributed system, when we want to equally distribute data among N amount of servers, this nature becomes really important, because when a request comes in, the hash function doesn't need to:
- Remember previous requests
- Know about other requests
- Keep track of which server handles what
- Store any historical information
So how would a hash map of 3 servers look like?
// Example of a hash map with 3 servers:
servers := []string{
"server1", // hash: 1000
"server2", // hash: 2000
"server3", // hash: 3000
}How would we distribute incoming data between the servers?
Let's say random data comes in, and we calculate its hash. It comes out as 1500. In our distribution function we would direct it to server2 because 2000 is the next highest hash, and so on and so forth.
func getServer(userID string, totalServers int) int {
hash := crc32.ChecksumIEEE([]byte(userID))
return hash % totalServers
// "randomData" will ALWAYS map to the same server number
// as long as totalServers stays the same
}The Problem
With this approach, if you have 3 servers and add a fourth one, roughly 80% of your data needs to be redistributed!
This is because the modulo operation creates a completely different mapping when the divisor (number of servers) changes.
2. Enter Consistent Hashing
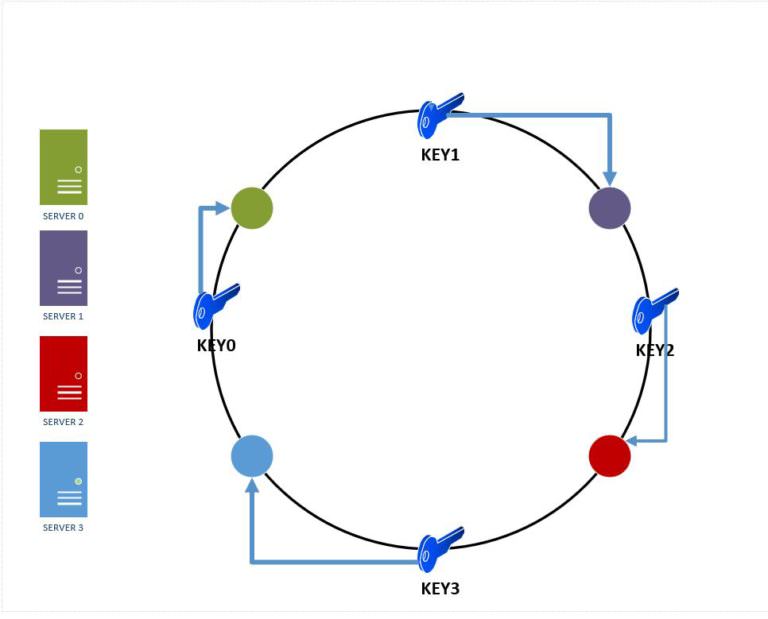
Consistent hashing solves this problem by creating a circular keyspace (often called a "ring") where both servers and data keys are mapped.
Here's how it works:
- Create a fixed-size hash space (typically 0 to 2^32 - 1)
- Map servers to multiple points on this circle using a hash function
- For each piece of data:
- Hash its key to get a position on the circle
- Move clockwise until you find the first server
- That server becomes responsible for the data
A visual representation of a hash ring can be seen below:
 source: acodersjourney
source: acodersjourney
Here's a basic implementation:
type Ring struct {
servers map[uint32]string // Map hash positions to server names
positions []uint32 // Sorted list of hash positions
}
func NewRing() *Ring {
return &Ring{
servers: make(map[uint32]string),
positions: make([]uint32, 0),
}
}
func (r *Ring) AddServer(server string, virtualNodes int) {
// Add multiple virtual nodes for each server to improve distribution
for i := 0; i < virtualNodes; i++ {
hash := crc32.ChecksumIEEE([]byte(fmt.Sprintf("%s-%d", server, i)))
r.servers[hash] = server
r.positions = append(r.positions, hash)
}
sort.Slice(r.positions, func(i, j int) bool {
return r.positions[i] < r.positions[j]
})
}3. Virtual Nodes for Better Distribution
Imagine you have just 4 physical servers, and each one gets mapped to just one point on the hash ring:
Ring position: 0 -------- 1000 -------- 2000 -------- 3000 -------- 4000
Server: S1 S2 S3 S4 (back to S1)This creates two issues:
- Uneven Distribution: If your hash function isn't perfect (they never are), you might end up with large gaps between servers. A server responsible for a larger arc of the ring gets more data.
- Hot Spots: If a server fails, its neighbor has to take all its load, potentially doubling that server's responsibility.
The solution: Virtual Nodes
Instead of mapping each server to one point, we map it to multiple points (often 100-200 points per server):
Ring position: 0 -- 100 -- 200 -- 300 -- 400 -- 500 -- ...
Server: S1 S3 S2 S1 S4 S2 ...Here's how it works in practice:
// Without virtual nodes
ring.AddServer("server1", 1) // Adds server1 at one position
// With virtual nodes (e.g., 100 virtual nodes)
ring.AddServer("server1", 100) // Adds server1 at 100 different positions
The benefits are:
- Better Distribution: Each server is responsible for many small sections of the ring rather than one large section. This averages out any non-uniformity in the hash function.
// Example showing how virtual nodes are created
func (r *Ring) AddServer(server string, virtualNodes int) {
for i := 0; i < virtualNodes; i++ {
// Create a unique hash for each virtual node
vnodeName := fmt.Sprintf("%s-vnode-%d", server, i)
hash := crc32.ChecksumIEEE([]byte(vnodeName))
// Map this hash position to the original server
r.servers[hash] = server
r.positions = append(r.positions, hash)
}
// Keep positions sorted for efficient lookup
sort.Slice(r.positions, func(i, j int) bool {
return r.positions[i] < r.positions[j]
})
}- Better Failure Handling: If a server fails, its load is distributed across all remaining servers rather than just one neighbor:
// Example of load distribution when a server fails
func (r *Ring) RemoveServer(server string, virtualNodes int) {
for i := 0; i < virtualNodes; i++ {
vnodeName := fmt.Sprintf("%s-vnode-%d", server, i)
hash := crc32.ChecksumIEEE([]byte(vnodeName))
// Remove all virtual nodes for this server
delete(r.servers, hash)
// Remove from positions slice (simplified)
// In practice, you'd use a more efficient removal method
}
}- Configurable Granularity: You can adjust the number of virtual nodes based on server capacity:
// More powerful servers can handle more virtual nodes
ring.AddServer("powerful-server", 200) // 200 virtual nodes
ring.AddServer("weaker-server", 50) // 50 virtual nodes
The beauty of this approach is that when you add or remove a server, only the keys that were mapped to that server's positions need to be redistributed. On average, if you have N servers and add one more, only 1/N of the keys need to move – much better than the ~80% with traditional hashing :)
Real-World Considerations
While the basic concept is elegant, production systems need to consider several additional factors:
- Replication: Store data on multiple consecutive servers for redundancy
- Weight: Some servers might have more capacity than others
- Failure Detection: Handle temporary server outages gracefully
- Consistency: Ensure all nodes agree on the ring state
Conclusion
Consistent hashing is a powerful technique that makes distributed systems more scalable and resilient.
While the basic concept is straightforward, the real power comes from understanding how to apply it to solve real-world problems. The implementation I've explored here is just the beginning.
Production systems often need to consider factors like:
- Network topology awareness
- Weighted distribution based on server capacity
- Active health checking and automatic failover
- Strong consistency guarantees